
C++ : Which data container to choose?
There are several types of data containers in the C++ Standard Library. We can quickly think of std::vector, std::list or std::map but there are several others and it is important to choose the right type of container according to the use that we will make of it. We will see below each type of container and their particularities.
C-style array
The C-style array, as its name suggests, is an array of elements from the C language. The number of elements in an array is static, which means that the size of the array is fixed once created. If we want to add or remove an element, we will have to recreate a new array with the new size and then copy the elements that we want to keep. The elements of an array are contiguous in memory. We can therefore directly access an element from its index, ie its position in the container. When we initialize an array, it is in fact a pointer to the first element of the array that is returned to us.
Example 1: Creating an array whose size is known at compile time
int myNumbers[] { 3, 5, 7, 12, 18, 21 };
cout << "First element: " << myNumbers[0] << " Last element: " << myNumbers[5] << "\n";
// Output : First element: 3 last element: 21
Example 2: Creating an array whose size is known at runtime
size_t nbElements;
cout << "Enter the number of array elements: ";
cin >> nbElements;
unique_ptr<int[]> myNumbers (new int[nbElements]);
for(size_t i=0; i<nbElements; i++) {
myNumbers[i] = i;
}
cout << "First element: " << myNumbers[0] << " "
"Last element: " << myNumbers[nbElements-1] << "\n";
// Input : 8
// Output : First element: 0 Last element: 7
It can be seen in the examples above that the elements are accessed via the indexing operator, but it is also possible to use pointer arithmetic to access the elements. As stated at the start, the variable used to access the array does not contain the elements of the array but it does contain a pointer to the first element of the array.
Let’s repeat the previous code example using pointer arithmetic to display the first and third element, that is, the elements at indexes 0 and 2.
Example 3: Accessing an Element via Pointer Arithmetic
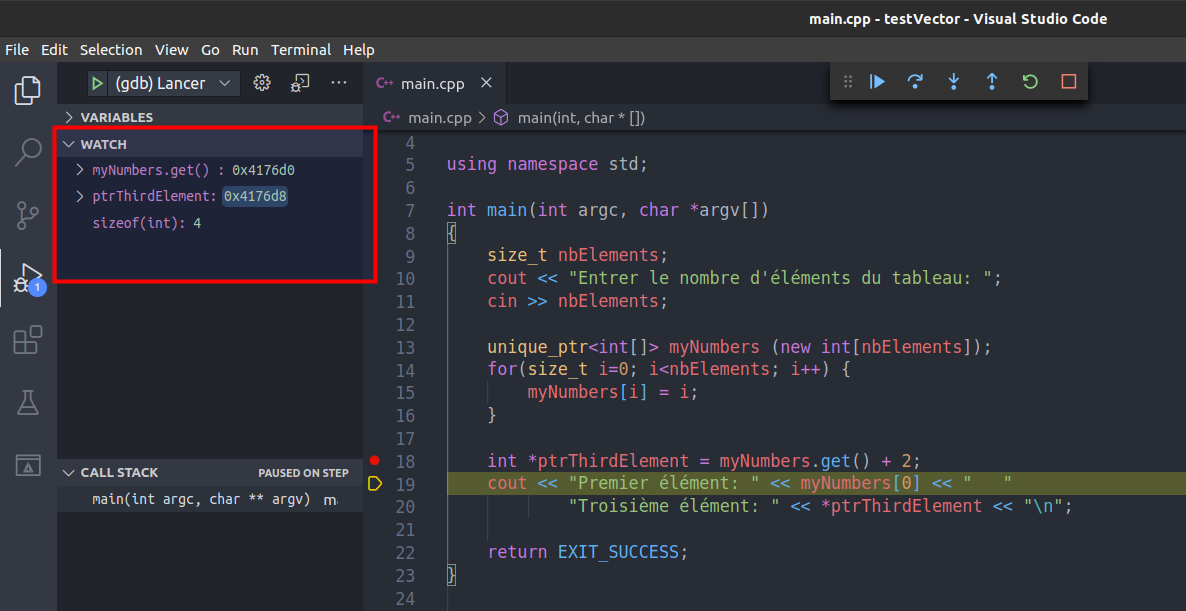
int *ptrThirdElement = myNumbers.get() + 2;
cout << "First element: " << myNumbers[0] << " "
"Third element: " << *ptrThirdElement << "\n";
We can see in the image below that myNumbers variable is actually a pointer that points to the memory address 0x4176d0 and knowing that the size of an int on my system is 4 bytes so we move 4 bytes for the second element therefore 0x4176d4 then another 4 bytes for the third element then 0x4176d8. It is of course necessary to dereference the pointer using the dereferencing operator (*) to be able to display its content.
The ++ operator on a pointer does not increment the address of the pointer by 1 but rather by once the size of the pointed element.
Regarding size, it is the responsibility of the developer to know and maintain the size of the array throughout its existence. If, for example, you want to pass a C-style array in a function, you must pass the pointer of the first element then the size of the array.
Example 4: Passing a C-style array to a function
void printArray(const unique_ptr<int[]> &p_MyNumbers, size_t p_NbElements)
{
cout << "First element: " << p_MyNumbers[0] << " "
"Last element: " << p_MyNumbers[p_NbElements-1] << "\n";
}
int main(int argc, char *argv[])
{
size_t nbElements;
cout << "Enter the number of array elements: ";
cin >> nbElements;
unique_ptr<int[]> myNumbers (new int[nbElements]);
for(size_t i=0; i<nbElements; i++) {
myNumbers[i] = i;
}
printArray(myNumbers, nbElements);
return EXIT_SUCCESS;
}
Passing a pointer and a size involves a risk of error on the part of the developer, so for arrays whose size is known at compile time, it is advisable to use a span. You can use the span class from the GSL (Guidelines Support Library) if the standard you are using is prior to C++20 and directly the std::span class if you are using the C++20 standard.
Example 5: Using a gsl::span
void printArray(gsl::span<int> &p_MyNumbers)
{
cout << "First element: " << p_MyNumbers[0] << " "
"Last element: " << p_MyNumbers[p_MyNumbers.size()-1] << "\n";
}
int main(int argc, char *argv[])
{
int myNumbers[] { 3, 5, 7, 12, 18, 21 };
gsl::span<int> spanMyNumbers(myNumbers);
printArray(spanMyNumbers);
return EXIT_SUCCESS;
}
As stated in the C++ Core Guidelines it is better to use the std::array for fixed-size containers rather than a C-style array. We will see the pros of the std::array in the next section. https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#slcon1-prefer-using-stl-array-or-vector-instead-of-a-c-array
Element access time: O(1)
Element insertion/removal time: O(n)
std::array
#include <array>
The number of elements in an array is fixed, that is, it cannot be changed once created. The std::array has the advantage of knowing its size compared to the C-style array so you don’t have to pass a pointer and size during a function call, you can just pass the array like in the example below:
Example 6: Passing an std::array by constant reference to a function
void printArray(const array<int, 6> &p_MyNumbers)
{
try {
cout << "First element: " << p_MyNumbers.at(0) << " "
"Last element: " << p_MyNumbers.at(p_MyNumbers.size()-1) << '\n';
}
catch(out_of_range const& err) {
cerr << "element out_of_range." << '\n';
}
}
int main()
{
array<int, 6> myNumbers { 3, 5, 7, 12, 18, 21 };
printArray(myNumbers);
return EXIT_SUCCESS;
}
It is also possible to pass an std::array by value to a function unlike the C-style array. See the post https://jdumais.blogspot.com/2020/04/c-passage-darguments-par-valeur-par.html for more details on the different modes of argument passing.
As you can see in the example above, one of the advantages of the std::array is the verification of bounds via the at method. If we try to access an element that is outside the array, an exception of type std::out_of_range will be triggered.
It is also possible to use the standard library iterators to access the different elements.
Example 7: Using Standard Library Iterators
void printArray(const array<int, 6> &p_MyNumbers)
{
//Display all elements
for(const auto &item : p_MyNumbers) {
cout << item << '\n';
}
}
int main()
{
array<int, 6> myNumbers { 3, 5, 7, 12, 18, 21 };
printArray(myNumbers);
return EXIT_SUCCESS;
}
Element access time: O(1)
Element insertion/removal time: O(n)
std::vector
#include <vector>
The vector is a container whose elements are contiguous in memory. It is therefore possible to directly access an element according to its index via the indexing operator or via the at method. The at method ensures that the supplied index is within bounds as shown in the std::array class.
The number of elements in a vector is dynamic, in other words its size can vary. The vector has a size and a capacity. The size returned by the size() method represents the number of elements present in the vector. The capacity is returned by the capacity() method and represents the number of elements that the vector can contain before being resized again. When the vector needs to be resized to include a new element, the capacity is doubled.
vector<int> myNumbers { 3, 5, 7, 12, 18, 21 };
// myNumbers.size() equal 6 and myNumbers.capacity() equal 6
myNumbers.emplace_back(24);
// myNumbers.size() now equal 7
// myNumbers.capacity() because the capacity has been doubled.
In versions prior to C++11, the add/insert methods were insert and push_back. All you had to do was construct the element to add and then call the method. The object was thus created then moved or copied in the vector. This therefore represents two operations. With the new emplace and emplace_back methods, just pass the arguments to create the object and the vector will take care of itself calling the constructor and creating the object directly in place. It’s more efficient that way.
Example 8: Demonstration of push_back vs emplace_back methods
class Student {
public:
Student(string firstName, string lastName)
: firstName(firstName), lastName(lastName)
{
cout << "The object is created.\n";
}
Student(Student&& other)
: firstName(std::move(other.firstName)), lastName(std::move(other.lastName))
{
std::cout << "The object is moved.\n";
}
Student& operator=(const Student& other) = default;
const string &getFirstName() const { return firstName; }
const string &getLastName() const { return lastName; }
private:
string firstName;
string lastName;
};
int main()
{
vector<Student> students;
students.reserve(2);
cout << "Adding student Joe Blow\n";
students.push_back(Student("Joe", "Blow"));
cout << "Adding student Jane Doe\n";
students.emplace_back("Jane", "Doe");
return EXIT_SUCCESS;
}
// Output:
// Adding student Joe Blow
// The object is created.
// The object is moved.
// Adding student Jane Doe
// The object is created.
As we saw in the previous example, the reserve keyword increases the capacity of a vector without adding elements to it. The slots for the future are therefore reserved, but not used. This makes it possible to avoid multiple resizings, and therefore copy costs in memory, when we know in advance what the number of elements required will be.
Containers whose elements are contiguous in memory can benefit from the speed of caching. When a request is made to read/write data in memory, the processor will not only load the contents of the memory address into its various levels of cache memory, but also a larger block of data knowing full well that the software will probably need these related items in future instructions. This can have a very big impact on the performance of a data container.
As the time to add/remove an element is in O(n) we will then be tempted to look towards the std::list if we really have a lot of operations of this kind.
As Bjarne Strupstrup points out in his book “A Tour of C++”, the vector should be your default container choice unless you have a strong reason to use another type of container.
Element access time: O(1)
Element insertion/removal time: O(n)
std::list
#include <list>
The std::list as its name suggests is a doubly linked list of items. This means that you can navigate the list in both directions: from start to end and from end to start, but unlike the previous containers, you cannot access an element directly.
The insertion/deletion time of an element is O(1) which is therefore a very big advantage if the size of the container is changed frequently.
Example 9: Demonstration of using a list (append to start, append to end, and traverse)
int main(int argc, char *argv[])
{
list<string> countries { "Canada", "France", "United States" };
countries.emplace_front("Belgium");
countries.emplace_back("Vanuatu");
//Display countries in order
for(const auto &country : countries) {
cout << country << '\n';
}
//Display countries in reverse order
for(auto iter=countries.rbegin(); iter != countries.rend(); iter++) {
cout << *iter << '\n';
}
//Display the third country of the list (France)
size_t i {0};
for(const auto &country : countries) {
if (i == 2) {
cout << country << '\n';
break;
}
i++;
}
return EXIT_SUCCESS;
}
The memory footprint of each element will therefore be larger, because for each element there will be a pointer to the previous element as well as a pointer to the next element.
Since the elements are not contiguous in memory, we will not be able to take advantage of the various optimizations related to memory cache. See Locality of reference for more info.
Element access time: O(n)
Element insertion/removal time: O(1)
std::forward_list
#include <forward_list>
The std::forward_list is exactly like the std::list except that the list can only be traversed in order. Each element only has a pointer to the next element, but not to the previous element. The forward_list therefore has a lighter memory footprint than the list.
Element access time: O(n)
Element insertion/removal time: O(1)
std::map
#include <map>
std::map is an association container between a key and a value. This container is normally implemented as a red-black binary tree. Container elements are sorted by key so if your key is a custom class you will need to implement comparison operators. The key in a std::map must be unique. If we try to add an element with the same key, the addition will be ignored without returning an error.
Example 10: Demonstration of using an std::map
int main(int argc, char *argv[])
{
map<int, string> employees
{
{320, "Joe Blow"},
{543, "Jane Doe"},
{735, "Aaron Black"}
};
employees.emplace(pair<int, string>(355, "John McClean"));
//Display employees in key order
for(const auto &employee : employees) {
cout << "ID: " << employee.first << " Name: " << employee.second << '\n';
}
//Output:
//ID: 320 Name: Joe Blow
//ID: 355 Name: John McClean
//ID: 543 Name: Jane Doe
//ID: 735 Name: Aaron Black
//Find employee 543
cout << "Employee 543: " << employees.at(543) << '\n';
//Output:
//Employee 543: Jane Doe
//Add an employee with the indexing operator.
employees[777] = "Byron Joe";
//Check if an employee exists
auto iter = employees.find(777);
if (iter != employees.end()) {
cout << "Employee 777: " << employees.at(777) << '\n';
}
//Output:
//Employee 777: Byron Joe
return EXIT_SUCCESS;
}
Association containers perform very well when searching by key.
Element access time: O(log n)
Element insertion/removal time: O(log n)
std::multimap
#include <map>
std::multimap is practically identical to the std::map except that the same key can be stored several times.
Example 11: Demonstration of searching an std::multimap for all elements of a same key
int main()
{
multimap<unsigned int, string> studentsByAge {
{12, "Joe Blow"},
{13, "Jane Doe"},
{12, "Aaron Black"}
};
const int AGETOFIND { 12 };
auto iter = studentsByAge.find(AGETOFIND);
cout << "Here is the list of all 12-year-old students:" << '\n';
while(iter != studentsByAge.end() &&
iter->first == AGETOFIND) {
cout << iter->second << '\n';
iter++;
}
return EXIT_SUCCESS;
}
//Output:
//Joe Blow
//Aaron Black
Element access time: O(log n)
Element insertion/removal time: O(log n)
std::set
#include <set>
std::set is also an association container, but it only contains a key and not a key and value like the std::map. In the example below, we will simulate a draw of 6 random numbers between 1 and 49 using a set.
Example 12: Demonstration of using an std::set
int main()
{
set<int> randomNumbers;
srand(static_cast<unsigned int>(time(nullptr)));
while(randomNumbers.size() != 6) {
//Choose a random number between 1 and 49
auto number = rand() % 49 + 1;
if (randomNumbers.find(number) == randomNumbers.end()) {
randomNumbers.emplace(number);
}
}
for(const auto number : randomNumbers) {
cout << number << " ";
}
cout << '\n';
return EXIT_SUCCESS;
}
//Output example:
//2 10 17 24 34 40
Element access time: O(log n)
Element insertion/removal time: O(log n)
std::multiset
#include <set>
std::multiset is practically identical to the std::set except that the same key can be stored several times.
Element access time: O(log n)
Element insertion/removal time: O(log n)
std::unordered_map, std::unordered_multimap, std::unordered_set et std::unordered_multiset
#include <unordered_map> and #include <unordered_set>
The four container implementations std::unordered_map, std::unordered_multimap, std::unordered_set and std::unordered_multiset are implemented as an hash table instead of a red-black tree.
It is important to choose a good hash function in order to minimize the number of collisions otherwise you really lose the advantage of hash tables.
Example 13: Demonstration of using an std::unordered_set using a hash function available in the standard library. The hash function will calculate the position based on the student’s first and last name.
class Student {
public:
Student(string firstName, string lastName)
: firstName(firstName), lastName(lastName) {}
bool operator==(const Student& rhs) const
{
return this->firstName == rhs.firstName &&
this->lastName == rhs.lastName;
}
const string &getFirstName() const { return firstName; }
const string &getLastName() const { return lastName; }
private:
string firstName;
string lastName;
};
class StudentHash
{
public:
size_t operator()(const Student &item) const
{
static hash<string> hashFunction;
return hashFunction(item.getFirstName() + item.getLastName());
}
};
int main()
{
unordered_set<Student, StudentHash> students;
students.emplace("Joe", "Blow");
students.emplace("Jane", "Doe");
students.emplace("Aaron", "Black");
for(const auto &student : students) {
cout << student.getFirstName() << " " << student.getLastName() << '\n';
}
return EXIT_SUCCESS;
}
Element access time: O(1) to O(n)
Element insertion/removal time: O(1) to O(n)
std::stack
#include <stack>
std::stack is a container that allows items to be added to a stack and popped in the reverse order they were added. It is a LIFO (last-in, first-out) data structure. An example is worth a thousand words.
Example 14: Demonstration of using an std::stack
int main()
{
stack<int> myNumbers;
//We are stack numbers 1, 2, 3, 4 and 5 in order.
for(int i=1; i<=5; i++) {
myNumbers.emplace(i);
}
//We unstack!
while(!myNumbers.empty()) {
cout << myNumbers.top() << '\n';
myNumbers.pop();
}
return EXIT_SUCCESS;
}
//Output:
//5
//4
//3
//2
//1
The top() method returns the item on top of the stack while the pop() method pops that same item off the stack.
Time to add/remove an element: O(1)
std::queue
#include <queue>
The std::queue is a container that allows items to be added to a queue and removed in the order they were added. It is a FIFO (first-in, first-out) data structure. Let’s go back to the std::stack example but using a std::queue.
Example 15: Demonstration of using an std::queue
int main()
{
queue<int> myNumbers;
//We queue numbers 1, 2, 3, 4 and 5 in order.
for(int i=1; i<=5; i++) {
myNumbers.emplace(i);
}
//We unqueue!
while(!myNumbers.empty()) {
cout << myNumbers.front() << '\n';
myNumbers.pop();
}
return EXIT_SUCCESS;
}
//Output:
//1
//2
//3
//4
//5
Time to add/remove an element: O(1)
std::priority_queue
#include <queue>
The std::priority_queue is a container that places the added elements according to the selected comparison function. By default, if no comparison function is specified, the values will be sorted according to the comparison function std::greater which will place the smallest value in the first position.
Example 16: Demonstration of using a std::priority_queue with the comparison function less.
int main()
{
priority_queue<int, vector<int>, less<int>> myNumbers;
for(int i : {12, 47, 55, 24, 36}) {
myNumbers.emplace(i);
}
//We clear the queue
while(!myNumbers.empty()) {
cout << myNumbers.top() << '\n';
myNumbers.pop();
}
return EXIT_SUCCESS;
}
//Output:
//55
//47
//36
//24
//12
Element access time: O(1)
Element insertion/removal time: O(log n)
std::deque
#include <deque>
std::deque is a queue that can grow in both directions. It has the advantage of offering O(1) performance on insertion/deletion at its 2 ends and an access time of O(1) to its elements. The elements of the deque are not necessarily stored contiguously in memory, but rather are stored as contiguous segments of fixed size.
Due to the management of these different memory segments, the deque has the disadvantage of having a larger memory footprint.
Element access time: O(1)
Element insertion/removal time (head and tail): O(1)
Element insertion/removal time (inside deque): O(n)
Conclusion
In conclusion, it is important to fully understand the different containers before making your choice. Each container has its advantages and disadvantages. Several points should be considered:
- Will the container size be fixed or variable?
- Does the order of the elements matter?
- What will be the way to access the elements? By their position? By their key?
- What will be the access rate versus the insertion/deletion rate? High change frequency?
- Will insertions/deletions be at the beginning, end, or elsewhere in the container?
We hope this article helps you make the right container choices for your future projects. :)